AI-powered Syllabus Extractor
Extracts unstructured course info from PDFs using NLP and regex pipelines.
May 2025
3 months
Problem
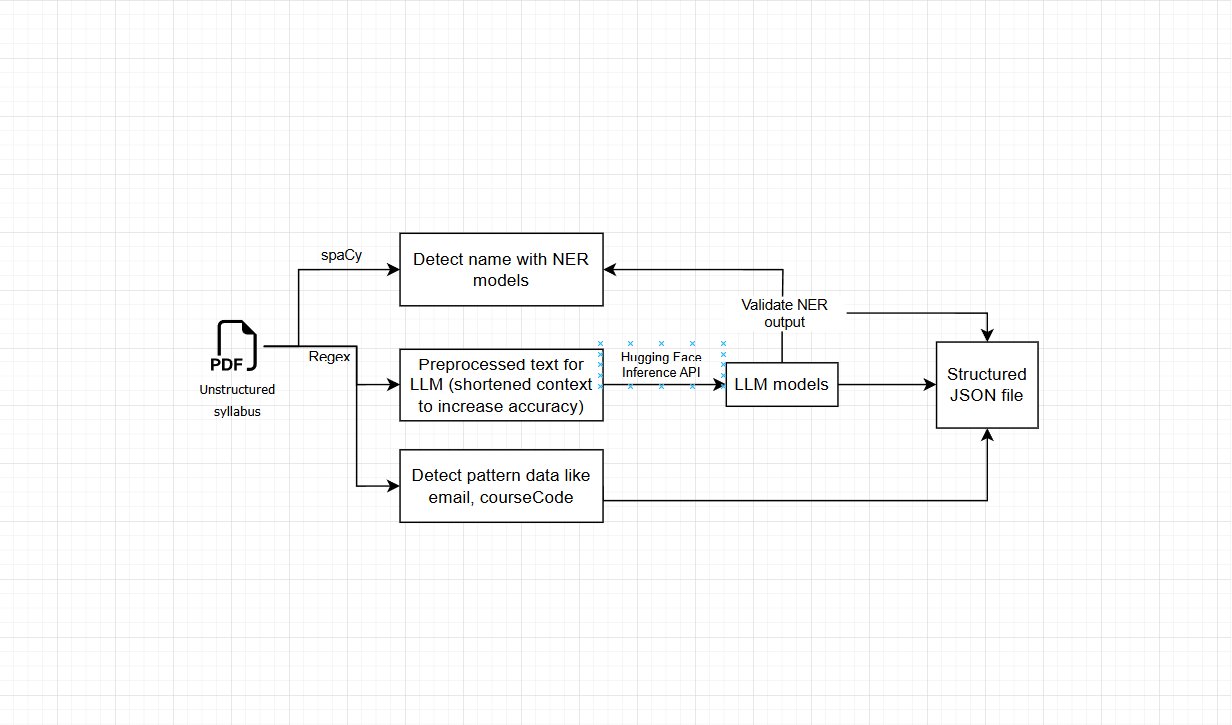
Each professor has a different way of writing the syllabus, which makes the structure of the document becomes very random. Manual extraction is time-consuming and error-prone, especially when dealing with various PDF formats and layouts.
Approach
Prototyped multiple parsing paths under strict LLM-token and latency budgets, benchmarked them, and selected a solution optimized for a serverless backend (low cold-start, low cost) with reliable schema extraction.
Tech Stack
PythonspaCyRegexHugging FaceLangChainLLMs
Result
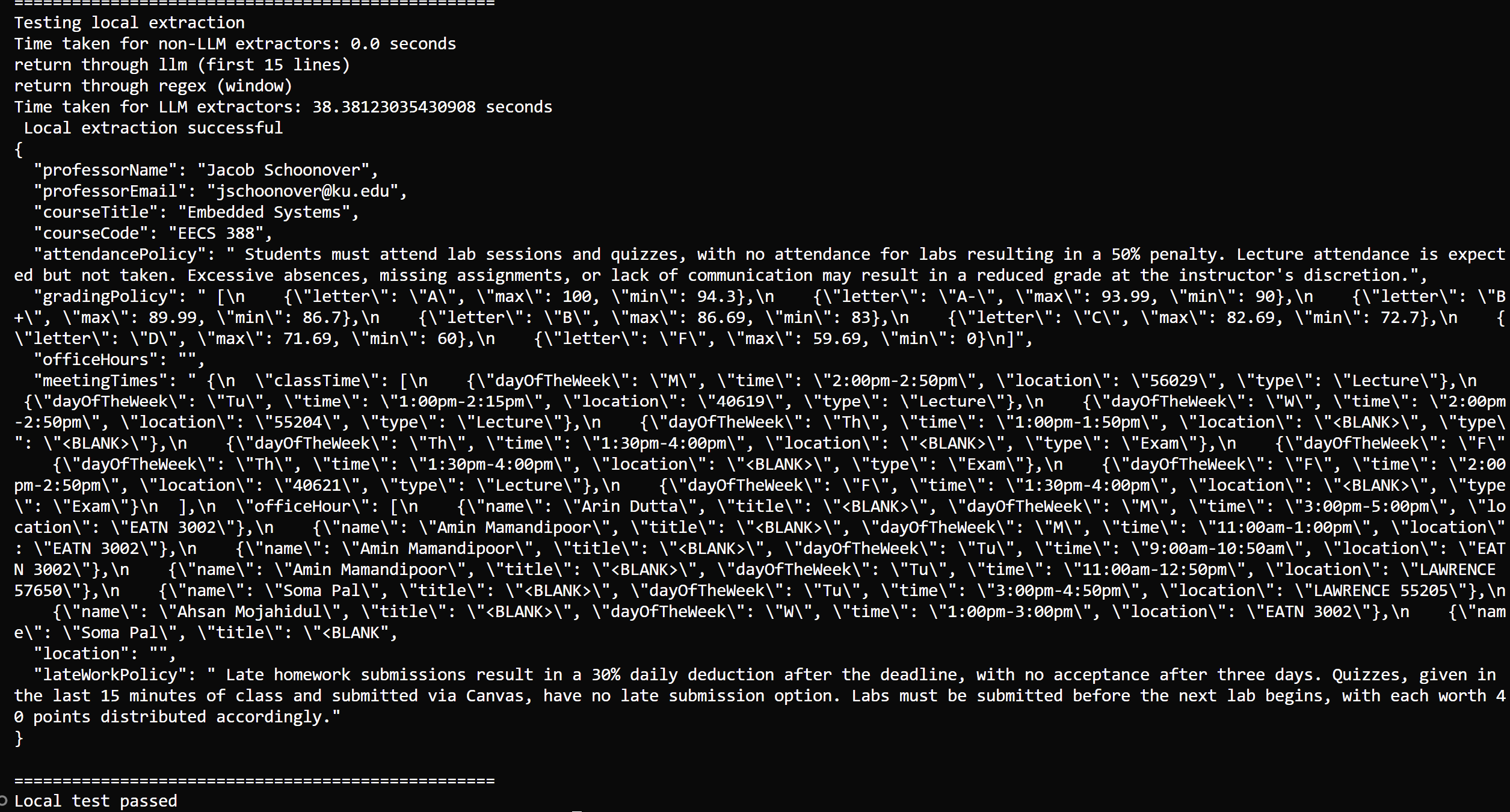
Successfully extracted course information with 90% accuracy across different PDF formats. Reduced manual processing time from minutes to seconds.
Screenshots